Coverserver voor UAntwerpen
Oktober 2023 - Mei 2024
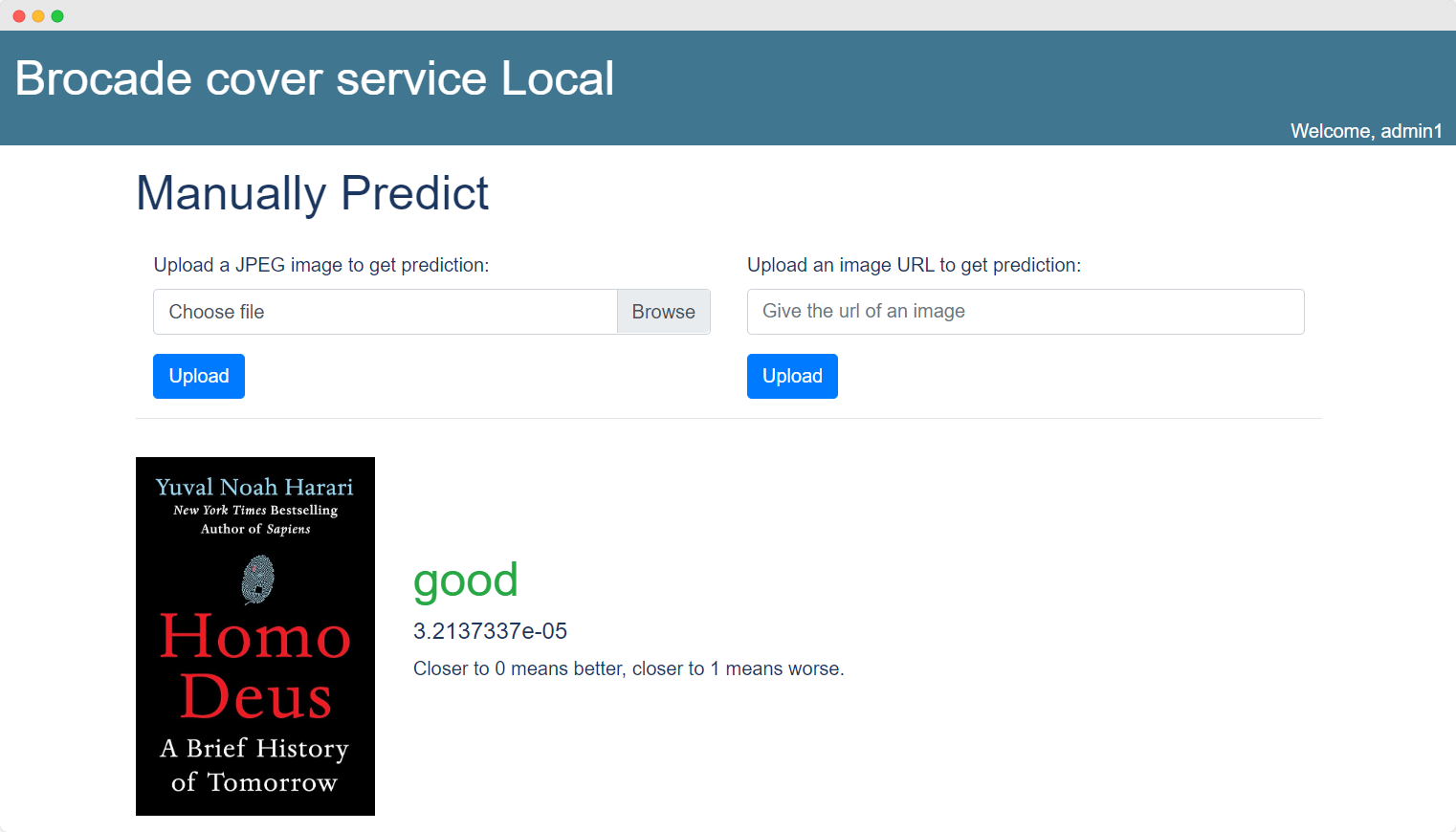
Voor Anet, de IT-dienst achter de UAntwerpen, heb ik een AI-model getraind dat goede en slechte coverfoto's kan onderscheiden. Hierdoor worden elke dag honderden coverfoto's gecontroleerd in een tiental bibliotheken.
Dit model is getraind op een dataset van 20.000 foto's, waarvan 12.000 goede en 8.000 slechte. Ik gebruikte een pretrained model 'Resnet50' als basis en trainde het verder met de dataset.
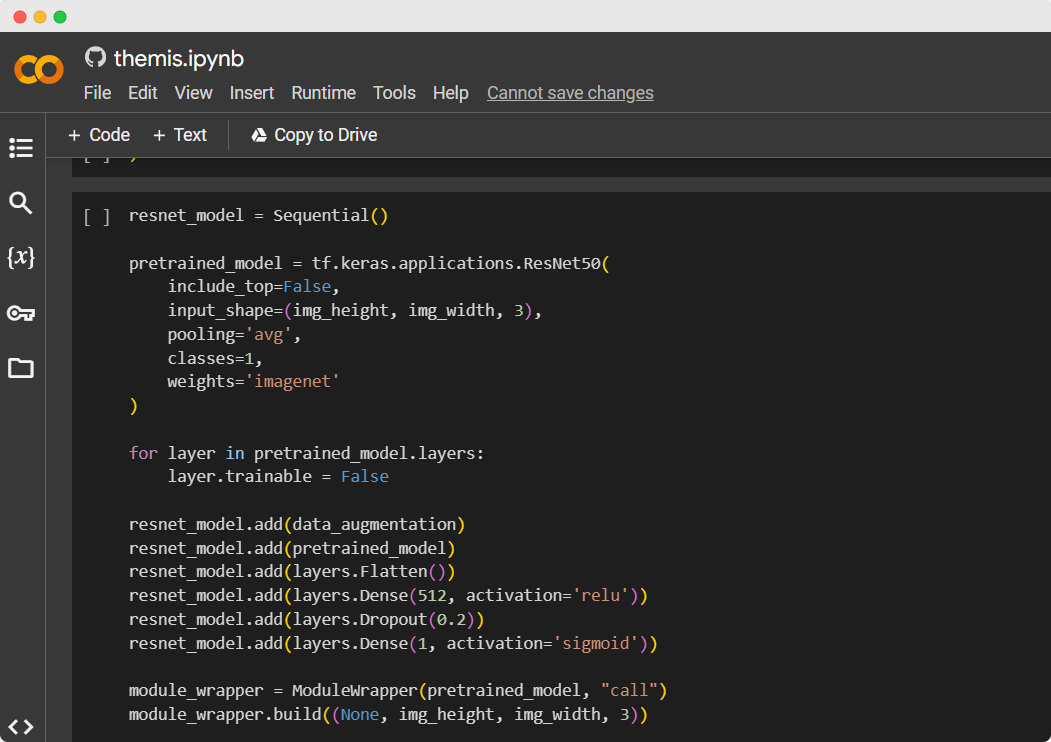
De catalogus van het Anet-netwerk telt circa 2.500.000 records, waaronder die van de bibliotheek van stad Antwerpen en het KMSKA. Na het trainen van het model heb ik het geïntegreerd, wat een uitdaging was vanwege de complexiteit van de codebase, vooral omdat ik geen ervaring had met het gebruikte framework Django.
Daarnaast heb ik ook een REST-API ontwikkeld die de communicatie tussen de front-end en het AI-model mogelijk maakt.
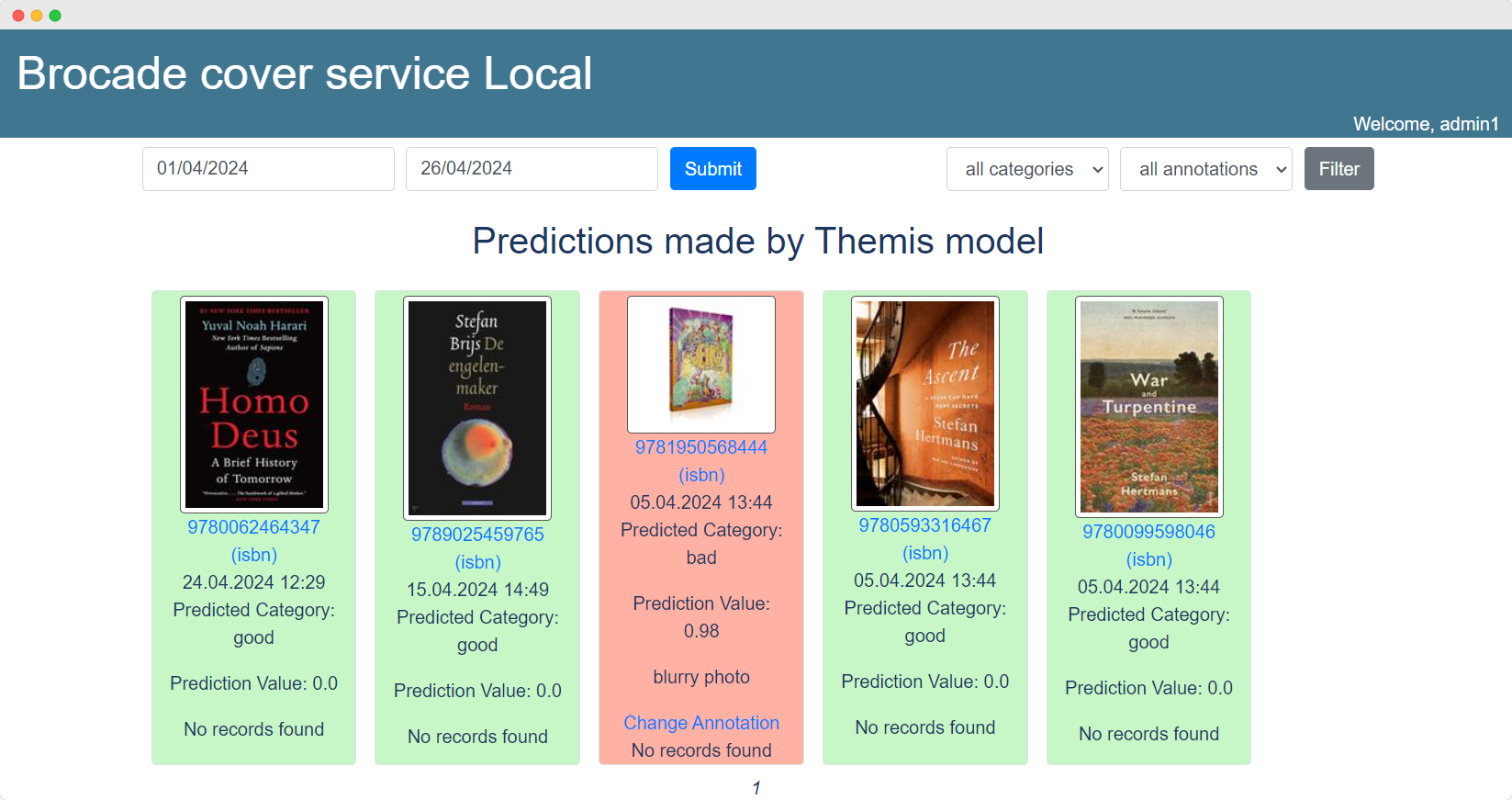
Alle voorspellingen die door het model worden gegenereerd, worden opgeslagen in de database. Coverfoto's kunnen worden geannoteerd met opmerkingen zoals 'te veel witruimte' of 'onscherp', met als doel in de toekomst een beter model te trainen.
Voor de ontwikkelaars heb ik ook twee schermen gemaakt waar de voorspellingen visueel worden weergegeven.